 Introduction
Introduction
Over the past year, since the inception of H2O, numerous papers on KV sparsity have flourished. However, a significant challenge in practical applications is the substantial gap between academic papers and real-world implementations. For instance, frameworks like vLLM use paging memory such as PagedAttention, which is incompatible with most sparse algorithms or performs worse than PagedAttention. These issues prevent sparse algorithms from being truly applied in production.
We referenced recent academic papers on KV sparsity over the past year and combined them with the optimization features of the vLLM framework, such as Continuous Batching, FlashAttention, and PagedAttention. We modified the VLLM framework based on KV sparsity and compared it with the state-of-the-art inference framework using the most commonly used models, parameters, and hardware online. This resulted in a 1.5x inference acceleration.
Before discussing KV sparsity, it is essential to mention the Massive Activations characteristic of LLMs. In LLMs, a small number of activation values are significantly more active than others, sometimes exceeding them by 100,000 times. In other words, a few tokens play a crucial role. Therefore, KV sparsity methods (i.e., retaining important tokens) can enhance inference performance.
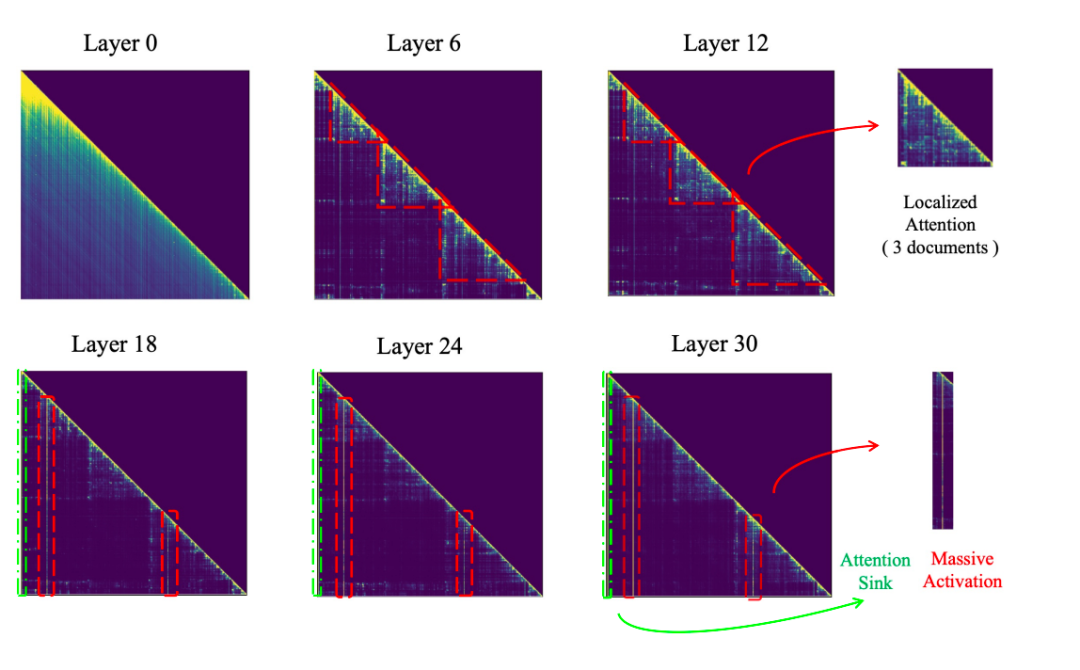
For specific analysis, refer to the data from Llama2 and Llama3, as shown in the following figure:
Activation Magnitudes (𝐳-axis) in LLaMA2-7B. 𝐱 and 𝐲 axes represent sequence and feature dimensions. For this specific model, we observe that activations with massive magnitudes appear in two fixed feature dimensions (1415, 2533), and two types of tokens—the starting token and the first period (.) or newline token (\n).
Unlike Llama2, Llama3 does not exhibit Massive Activations characteristics in all layers. Lower layers show uniform distribution characteristics, middle layers show localized attention characteristics, and only upper layers exhibit Massive Activations characteristics. This is why models like Llama3 use hierarchical sparsity.
The attention patterns of retrieval-augmented generation across layers in LlaMa (Touvron et al., 2023a;b) reveal that in the lower layers, the model exhibits a broad-spectrum mode of attention, distributing attention scores uniformly across all content. In the middle layers, attention becomes more localized within each document, indicating refined information aggregation (dotted red triangular shapes in layers 6 and 10). This culminates in the upper layers, where "massive attention" focuses on a few key tokens (concentrated attention bars after layer 18), efficiently extracting essential information for answers.
Having introduced the Massive Activations characteristic of LLMs, we have a basic understanding of the principles of KV sparsity. Next, we will delve into how KV sparsity is implemented. During the inference process of large models, graphics card capacity, computational power, and IO are often the three major bottlenecks. To avoid repeated calculations, KV is often cached, leading to significant GPU memory usage, and computational and IO bottlenecks in the Prefill and Decode stages.
Our modification of vLLM is based on the Massive Activations characteristic of LLMs to achieve hierarchical sparsity (i.e., different layers have different sparsity levels), significantly reducing KV overhead and accelerating LLM inference.
As shown in the figure above, if we perform KV sparsity at different layers of the model during inference, we can delete KV with lower scores through an elimination strategy while retaining KV with higher scores and closer distances, saving memory and reducing computational and IO overhead, ultimately achieving inference acceleration.
Inference Acceleration Results
The most critical question is how KV sparsity performs in vLLM. Let's first introduce the performance evaluation results.
Inference Performance
In practical applications of LLMs, input/output lengths of 4000/500 are the most common, and the RTX4090 graphics card is one of the most widely used in the industry. We conducted batch performance comparison tests based on this. The control group was vLLM0.6.1.p2, and the experimental group was PPIO Sparse0.5.1 (a kv sparse modification version of vLLM 0.5.1). Both were subjected to multi-round performance comparison tests, with the main indicators being TTFT (first token latency, affecting user experience) and Throughput (actual inference speed).
The final test results showed that through KV sparsity, while ensuring TTFT is usable (P50 within 1 second), the throughput of vLLM can be increased by about 1.58 times.
As shown in the table above, in scenarios with large Batch Size, vLLM0.6.1.p2 has reached its limit at a concurrency level of 10, while PPIO Sparse0.5.1 can still maintain stable TTFT performance at a concurrency level of 20, ensuring the performance stability of KV sparsity in actual production.
Model Performance
Since KV sparsity is a lossy compression algorithm, model performance evaluation is equally crucial. We conducted performance evaluations such as mmlu on Llama3-8B and found that the accuracy loss was generally within 3%. As shown in the table below, we tested model performance through mmlu and humanities:
Additionally, for long text scenarios in actual business, we conducted QA task evaluations with input lengths of 7k-30k and a compression ratio of over 10 times. The results showed an overall accuracy loss of about 10%.
Key Technologies
Hierarchical Sparsity and Tensor Parallelism
vLLM itself uses an Iteration-Level Schedule, commonly known as Continuous Batching. This scheduling strategy does not wait for each sequence in the batch to complete generation but achieves iteration-level scheduling, resulting in higher GPU utilization than static batch processing. As mentioned at the beginning of the article, models like Llama3-8B inherently have hierarchical sparsity characteristics. Our modification based on Continuous Batching naturally encountered a series of challenges.
The first problem to solve is memory management across different layers. Since vLLM uses a unified paging memory management mode across all layers, and the queue strategy can only choose between Full Cache and Sliding Window, we adjusted the underlying structure of vLLM to support both Full Cache and Sliding Window, allowing different layers to freely choose Full Cache or Sliding Window, ultimately achieving different sparsity levels across layers. The corresponding structure is shown in the figure below:
The overall adjustments can be divided into three stages:
-
Service Startup Phase: During service startup, the remaining space is primarily used to initialize the space allocation for three layers and initialize the Metadata structure. The original vLLM is equivalent to a full Full Cache and does not consider memory allocation logic for different layers.
-
Step Preparation Phase: During the initialization of vLLM's step, i.e., the block manager/model_runner methods, different block table management strategies are applied to different layers to control KV update mechanisms. As shown in the figure, the first three layers use the Full Cache mechanism, storing all KV, while layers above the third use the Sliding Window to automatically replace KV with the lowest scores. This method flexibly specifies the memory space required by each layer, saving space and maximizing the effect of the sparse algorithm.
-
Sparsification Calculation Phase: This phase usually occurs after model execution, where the sparsification score obtained from the calculation is used to perform the sparsification operation. This step needs to consider the compatibility of Tensor Parallelism, CUDA graphs, GQA, etc. In practical engineering, Tensor Parallelism requires special attention. As shown in the figure, in a multi-GPU scenario, a reasonable segmentation mechanism is needed to limit KV sparsification operations within each GPU to avoid communication between GPUs. Fortunately, the Attention unit is based on ColumnLinear segmentation, making implementation relatively easy.
Above, we mainly discussed the modifications at the framework level to support hierarchical sparsity in vllm. Next, we will focus on the optimization at the CUDA level.
Attention Transformation
The transformation at the CUDA level mainly focuses on the Attention calculation unit, i.e., the transformation of FlashAttention and PagedAttention. PagedAttention is relatively simple, so we will focus on the transformation of FlashAttention.
First, let's review the Attention calculation formula:
As shown in the figure, the softmax calculation process is based on the QK calculation and is a 2-pass algorithm (looping twice). However, the final calculation target O can be achieved through the FlashAttention algorithm with a 1-pass (looping once). The implementation logic of FlashAttention can be referenced from the screenshot of the FlashAttention2 paper below. In summary, by traversing KV in blocks with Q, gradually updating O/P/rowmax, and finally dividing O by ℓ, the 1-pass FlashAttention calculation can be achieved.
For our implementation of KV sparsity, it is crucial to note that during the FlashAttention calculation, the rowmax/ℓ (global maximum and cumulative values) required for softmax have already been calculated, but FlashAttention does not return these results.
With a basic understanding of FlashAttention, let's discuss the sparse scoring formula in papers like PYRAMIDKV, as shown below:
In the above formula, A represents the softmax score, and S represents the sum of the nearest a softmax scores. As mentioned earlier, softmax is inherently a 2-pass algorithm and cannot be directly integrated into FlashAttention, indicating that sparse scoring cannot be achieved in 1-pass.
As mentioned in the previous section, although FlashAttention does not output softmax scores, it calculates intermediate values like rowmax/ℓ. Therefore, we referenced the Online Softmax: 2-pass algorithm and used the output of rowmax/ℓ to achieve the specific scoring S for KV sparsity. In engineering, the following improvements to FlashAttention are needed to meet the requirements:
-
FlashAttention Outputs rowmax/ℓ: Since rowmax/ℓ are maximum or cumulative values with a small data volume, they have little impact on FlashAttention. By reusing rowmax/ℓ, an additional 1-pass can be avoided, thereby improving overall computational efficiency.
-
Add Online Softmax Step: Based on FlashAttention, calculate the softmax score (1-pass logic) using the formula p=e((kq)-row_max)/ℓ, then perform row summation to calculate the sparse score S.
In the code implementation of Online Softmax, two details require special attention:
-
Adjust Loop Order: Since S is based on the scoring summation in the k dimension, compared to qk in attention, the calculation order in Online Softmax needs to be adjusted to kq. This avoids invalid communication between blocks (i.e., converting col_sum to row_sum, all calculations are completed in registers).
-
Start and End Positions of q: Due to causal encoding and the logic of summing the nearest a values, not all q need to be traversed with k. As shown in the figure with 0/1 mask marks, the start and end positions of q can determine whether the corresponding block needs to be calculated, significantly saving computational resources. For example, if the input prompt length is 5000 and the nearest a length is 256, conventional calculations require 50005000 calculations, while recording start and end positions only requires 5000256 calculations, improving computational efficiency.
The work done by PagedAttention is similar to FlashAttention, aiming to calculate the final S, and is not detailed here.
Conclusion
Our modified PPIO Sparse0.5.1 based on vLLM 0.5.1 currently mainly supports models like Llama3-8B and Llama3-70B. The inference mode supports CUDA graphs, and the deployment environment is primarily on consumer-grade graphics cards like RTX 4090. There is still significant room for optimization in both engineering and algorithms.
Compared to the latest vLLM-0.6.2 version, the following features are not yet supported:
- Chunked-prefill
- Prefix caching
- FlashInfer and other non-FlashAttention attention backends
References
- H2O: Heavy-Hitter Oracle for Efficient Generative Inference of Large Language Models
- Keyformer: KV Cache Reduction through Key Tokens Selection for Efficient Generative Inference
- SnapKV: LLM Knows What You are Looking for Before Generation
- PyramidKV: Dynamic KV Cache Compression based on Pyramidal Information Funneling
- PyramidInfer: Pyramid KV Cache Compression for High-throughput LLM Inference
- MiniCache: KV Cache Compression in Depth Dimension for Large Language Models
- Layer-Condensed KV Cache for Efficient Inference of Large Language Models
- TriForce: Lossless Acceleration of Long Sequence Generation with Hierarchical Speculative Decoding
- CacheBlend: Fast Large Language Model Serving for RAG with Cached Knowledge Fusion
- KV-Runahead: Scalable Causal LLM Inference by Parallel Key-Value Cache Generation
Content Recommendations
On August 18-19, 2024, the AICon Global AI Development and Application Conference was successfully held in Shanghai, gathering over 60 industry pioneers to comprehensively analyze topics such as large model training and inference mechanisms, multimodal fusion, agent advancements, retrieval-augmented generation strategies, edge model optimization and applications. With guest authorization, "AI Frontiers" has exclusively compiled a collection of presentation slides. Don't miss out. Follow "AI Frontiers" and reply with the keyword "PPT" to get it for free.
Conference Recommendations
The grand finale of 2024: On December 13-14, the AICon AI and Large Model Conference will be held in Beijing. From RAG, Agent, multimodal models, AI Native development, embodied intelligence, to AI-driven driving, performance optimization and resource planning, 60+ seasoned experts will gather to deeply analyze relevant implementation cases and discuss cutting-edge technology trends. The conference is now open for registration. For details, please contact the ticketing manager at 13269078023.