字节笔记本
2026年2月21日
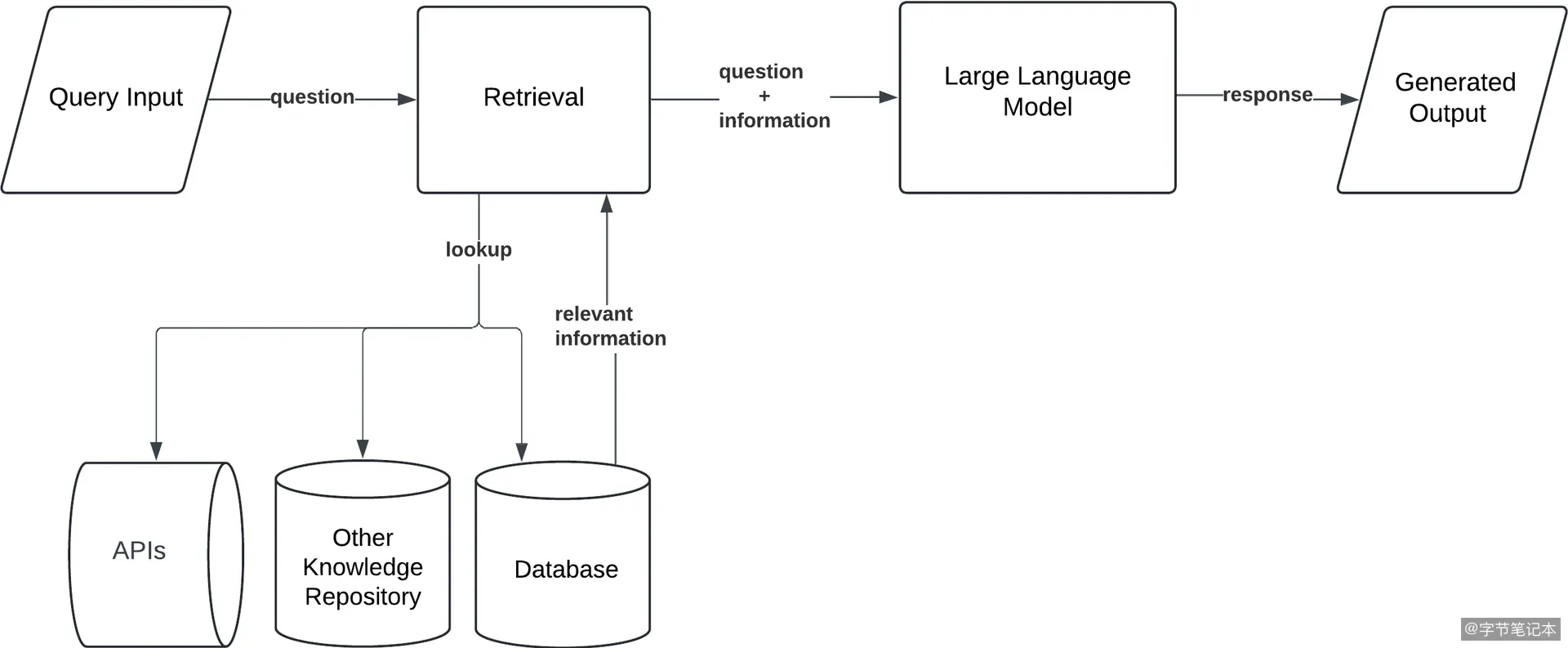
RAG 落地为什么难?七个常见坑和应对办法
RAG 系统的落地比很多人想象的难。本文基于斯坦福论文《Seven Failure Points When Engineering a RAG System》,结合实际开发经验,梳理了 RAG 系统中最常见的几个坑和应对办法。
格式错误:模型不听话
你让模型输出 JSON,它给你一堆自由文本。你想要表格,它给你 Markdown。这是 RAG 开发中最常见的挫败感来源之一。
几个实用的解决思路:
- 写更明确的 prompt。别指望模型猜你要什么格式,直接给示例。
- 用输出解析器兜底。LlamaIndex 支持和 Guardrails、LangChain 的输出解析模块集成,把模型的输出强制解析成你要的结构。
- 用 Pydantic 定义数据模型。LlamaIndex 支持三种 Pydantic 程序:文本完成版、函数调用版、预设版。定义好输出 schema,模型自动按规范输出。
- OpenAI JSON 模式。设
response_format为json_object,模型只输出能解析的 JSON。但注意,这只保证格式是 JSON,不保证内容符合你的 schema。
内容缺失:瞎编一气
这是最危险的。知识库里没有答案,RAG 系统不是承认"我不知道",而是编一个看起来很合理的答案。用户被误导,后果不堪设想。
两个层面解决:
优化数据源。 "输入什么,输出什么。"如果源数据质量差、充斥着冲突信息,怎么优化 RAG 流程都没用。数据治理是前置条件,不是可选项。
改进提示方式。 在 prompt 里加一句"如果你无法确定答案,请说明你不知道"。不能百分百保证有效,但实测下来确实能显著减少幻觉。
错过关键文档:答案就在那,但没找到
检索到了相关文档,但最关键的文件排名靠后,没进 top-k,模型看不到正确答案。
两种解决思路:
重排序。 先检索 top-10 结果,再用 CohereRerank 等模型重排序,最后取 top-2。LlamaIndex 有对比实验证明这种做法比直接取 top-2 效果好。
调参。 chunk_size 和 similarity_top_k 直接影响检索质量。chunk 太小会丢失上下文,太大又会导致噪声太多;top_k 太小会错过关键文档,太大又会让噪声淹没有用信号。需要根据具体场景调。
脱离上下文:检索到了但没用上
检索到了含有答案的文档,但这些文档在整合阶段被忽略了。数据库返回了大量文档,LLM 在整合过程中丢了关键信息。
解决方向:
- 用更好的检索策略。LlamaIndex 提供了从基础到高级的一系列检索方式:自动检索、知识图谱检索器、组合检索器等。
- 微调 embedding 模型。如果你用的是开源模型,微调 embedding 可以显著提高检索准确性。
未能提取答案:信息太多,找不到重点
上下文里信息量太大,干扰信息和矛盾信息混在一起,LLM 提取不到关键内容。
三个解法:
清理数据。 再次强调数据质量。垃圾进,垃圾出。
上下文压缩。 LongLLMLingua 技术可以在检索后压缩上下文,去掉噪声,保留和问题相关的内容。压缩后再喂给 LLM,提取准确率会提高。
重排序。 研究发现,LLM 对上下文开头和结尾的信息处理得更好,中间的信息容易被"丢失在中间"。LongContextReorder 可以重新排列节点顺序,把最相关的内容放到首尾位置。
回答太宽泛:不够具体
答案没错,但缺少细节。比如问了一个很具体的技术问题,模型给了一段放之四海而皆准的泛泛而谈。
这通常不是 LLM 的问题,而是检索的问题。文档里确实有详细的答案,但没被检索到。
LlamaIndex 提供了几种高级检索方法来解决这类问题:从细节到全局的检索、围绕特定句子的检索、逐步深入的递归检索。
回答不全面:只答了一部分
比如问"文档 A、B、C 分别讨论了哪些主题?",简单的 RAG 模型可能只回答了其中一两篇的内容,漏掉了其他的。
解决办法是加一个查询理解层:在实际检索之前,先对查询进行优化。LlamaIndex 支持四种方式:
- 路由优化:根据查询内容,分发给不同的检索工具
- 查询改写:保持工具不变,但用不同的措辞重新表达查询,提高覆盖率
- 细分问题:把大问题拆成几个子问题,分别检索
- ReAct Agent:让 agent 自己决定用什么工具、构造什么查询
假设性文档嵌入(HyDE)是一种常用的查询改写技术:先让 LLM 根据原始查询生成一个假设性答案,再用这个答案去做 embedding 检索,效果比直接用原始查询好。
数据处理能力:跑不动
文档量大的时候,RAG 系统的数据处理管道可能成为瓶颈。分词、embedding、入库,串行执行的话速度很慢。
LlamaIndex 的解决方案是并行处理。IngestionPipeline 支持设置 num_workers,实测最多能提升 15 倍的处理速度。
小结
上面列了七个问题,但 RAG 落地的坑远不止这些。每个问题单独拿出来都可以写一篇长文。在实际项目中,这些问题往往是交织在一起的——格式错误可能加剧内容缺失,检索不准又让回答过于宽泛。
如果只能给一条建议的话:先把数据治理做好。RAG 系统的上限不取决于你用了多先进的检索策略或多强大的 LLM,而取决于你喂给它的数据质量。