字节笔记本
2026年5月30日
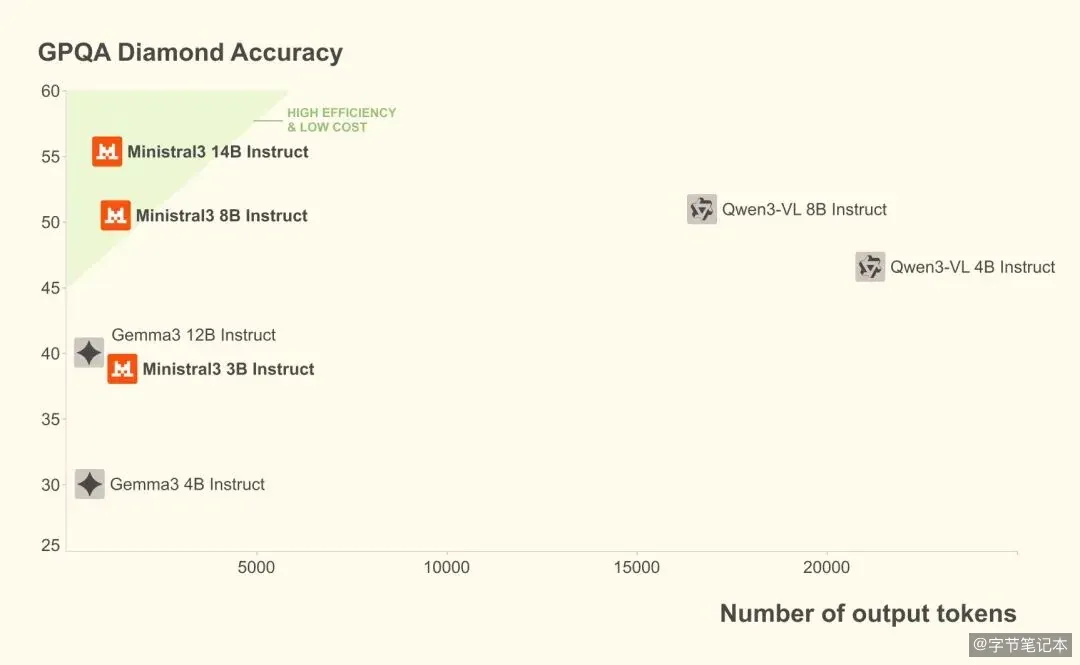
Mistral 3 把 14B 模型做到了 85% GPQA,小模型的天花板又被抬高了
开源大模型领域正在形成一个有趣的趋势:模型不再一味求大,而是开始在"小"上做文章。
Mistral 最新发布的第三代模型,最引人注目的不是那个 675B 参数的稀疏混合专家大模型,而是那个只有 14B 参数的 Ministral 3。
14B 在 GPQA 测试中拿下了 85% 的准确率。这个数字意味着什么?它超过了绝大多数同规模的开源模型,甚至在部分基准上逼近了更大规模的闭源模型。一个能在消费级显卡上运行的模型,做到这个程度,才是真正的实用突破。
Mistral 3 系列包含四个模型:Ministral 14B/8B/3B 三个密集小模型,以及 Mistral Large 3(675B 总参/41B 激活)的 MoE 架构。全部采用 Apache 2.0 许可,这意味着企业可以自由商用。
部署门槛被压到了很低的水平。14B 模型只需 24GB 内存即可本地运行,8B 模型在 16GB 显存的消费级显卡上就能跑。有开发者在 RTX 3090 上实测,14B 推理版本每秒可处理 42 个 token。Ollama 和 vLLM 都已在第一时间提供支持,一行命令即可启动。
真正值得关注的不是参数和跑分本身,而是这背后释放的信号:高质量开源模型的可及性正在快速提升。当 14B 模型能在个人电脑上跑出接近顶尖模型的性能时,AI 应用的部署逻辑会发生变化。不再需要昂贵的云端推理集群,不需要复杂的分布式部署,一个开发者、一台笔记本、一个模型,就能构建生产级的 AI 应用。
Mistral 在模型架构上的选择也值得留意。Large 3 采用的稀疏 MoE 架构,41B 激活参数即可调动 675B 的参数量,这是目前大模型领域效率最高的架构路线之一。而小模型全线支持多模态和 256K 长上下文,说明 Mistral 认为这些能力正在从"高端特性"变成"基础标配"。
模型的门槛在下沉,能力的基线在上升。对于开发者来说,这意味着现在是开始构建 AI 应用最好的时机,不是因为模型最强,而是因为好模型已经足够便宜、足够容易到手。