字节笔记本
2026年5月30日
多模态知识库不是把图片塞进数据库那么简单
多模态知识库是一个被过度使用、却很少被真正理解的概念。
大多数人对它的认知停留在"往数据库里塞图片和视频"的层面。但多模态知识库的真正挑战不在于存什么格式的数据,而在于如何让不同模态的信息之间对齐语义并支持推理。
构建多模态知识库面临三重断层。
第一层是表征断层。文本可以用 BERT 或 GPT 系列模型编码为稠密向量,图像需要用 ViT 或 CLIP,音频需要 Whisper 或 HuBERT。不同模态的模型训练目标和语义空间完全不同。一张猫的图片和一段描述猫的文字,在各自的向量空间里并没有天然的对应关系。所谓的多模态对齐,本质上是在不同模态的嵌入空间之间架桥。CLIP 用对比学习在 4 亿图文对上训练出一个共享空间,才让"一张图片"和"一段文字"在向量空间里可以做相似度计算。但这种对齐仍然粗糙,CLIP 能匹配"一只橘猫坐在沙发上"和对应的图片,但如果是更专业的场景,比如 CT 影像和放射科报告,通用模型的效果就急剧下降。
第二层是存储断层。向量数据库擅长做相似性检索,知识图谱擅长做关系推理。但一个多模态知识库往往需要同时满足这两者。目前的做法是混合架构:向量库存非结构化数据的嵌入,图谱库存实体之间的关系,中间靠一个调度层来路由查询。问题是,当用户输入一张图片作为查询时,系统需要先用视觉模型提取特征,在向量库中检索相似的视觉内容,再根据检索结果在图谱中做关联推理。这两个步骤之间的误差会累积。向量检索的 Top-5 如果本身就偏了,后续的图谱推理就失去了意义。
第三层是推理断层。知识库的终极价值不是存储,而是基于存储的知识辅助决策。但多模态推理比单模态复杂得多。医生看 CT 影像时,不仅看图像本身,还会结合病历文本、检验报告、用药记录做综合判断。多模态 AI 知识库需要模拟这种能力,但目前的主流做法还是分阶段管线:视觉模型提取图像特征,NLP 模型处理文本,然后在决策层做特征拼接。这种"后融合"策略的问题在于,模态间的交互发生在决策层而非理解层,模型实际上并没有真正"理解"图像和文本之间的深层关联,只是在最后一步做了特征拼接。

当前工业界的典型实践是"向量库 + 图谱库"的混合存储。向量库负责非结构化数据的召回,图谱库负责结构化关系的推理。数据入库时走两条路:文本、图片等非结构化数据经过 Embedding 模型转为向量存入向量库;同时,实体和关系通过 NER 和关系抽取写入图谱。查询时也分两路:自然语言查询先做向量检索拿到候选,再结合图谱进行多跳推理,最终融合排序。
这种方案的优势是各司其职、技术成熟,但代价是架构复杂、维护成本高。对于大多数团队来说,建议先从纯向量检索起步,只处理单模态数据,等验证了 RAG 的核心链路之后再逐步加入多模态和图谱能力。一步到位往往意味着一步都到不了。
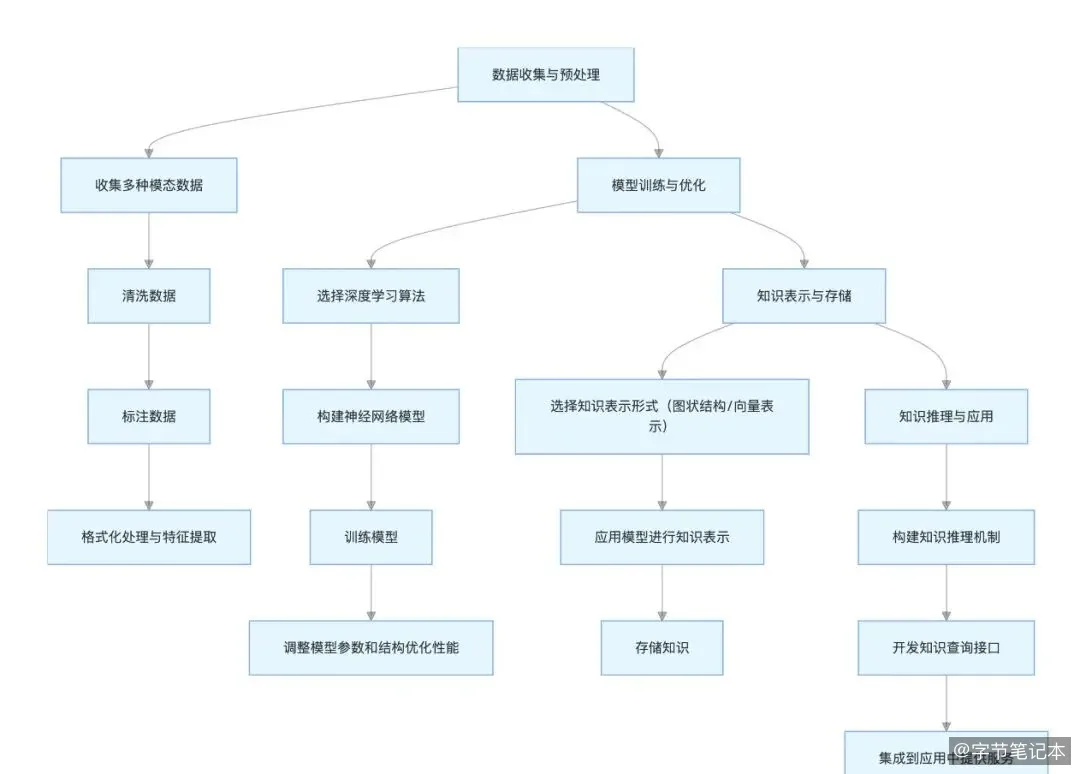
多模态知识库的成熟度,取决于你对这三重断层的理解和取舍。不需要一开始就解决所有问题,但要清楚自己在哪个断层上。