字
字节笔记本
2026年5月30日
RAG 文档切太细丢上下文,切太粗不精准,Parent-Child 分割刚好
API中转
¥120
RAG 系统的检索精度,很大程度上取决于一个看似简单的决策:文档该切多大?
切大了,上下文完整但检索不精准,用户问一个细节问题,返回一整篇文章。切小了,检索精准但上下文割裂,模型拿到的是碎片化信息,无法理解完整的语义。
Parent-Child 分割试图同时解决这两个问题。方案是:把文档切成两种尺寸的块。大块(Parent)负责提供上下文,小块(Child)负责精确匹配。
具体实现使用 LangChain 的 ParentDocumentRetriever:
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import TextLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.storage import InMemoryStore
# 加载文档
loaders = [
TextLoader("example_data/doc1.txt"),
TextLoader("example_data/doc2.txt"),
]
docs = []
for loader in loaders:
docs.extend(loader.load())
# Parent Chunk: 2000字符,提供完整上下文
parent_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
# Child Chunk: 400字符,负责精确匹配
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
# 创建向量存储和检索器
vectorstore = Chroma(
collection_name="split_parents",
embedding_function=OpenAIEmbeddings()
)
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
parent_splitter=parent_splitter,
)
retriever.add_documents(docs)检索时分两步走。先用 Child Chunk 做精确匹配,定位到最相关的片段,然后根据关联关系找到对应的 Parent Chunk,返回完整的上下文:
python
# 搜索相似的 Child Chunks
sub_docs = vectorstore.similarity_search("justice breyer")
print(sub_docs[0].page_content) # 精确匹配的小片段
# 获取完整的 Parent Chunks
retrieved_docs = retriever.get_relevant_documents("justice breyer")
print(len(retrieved_docs[0].page_content)) # 包含完整上下文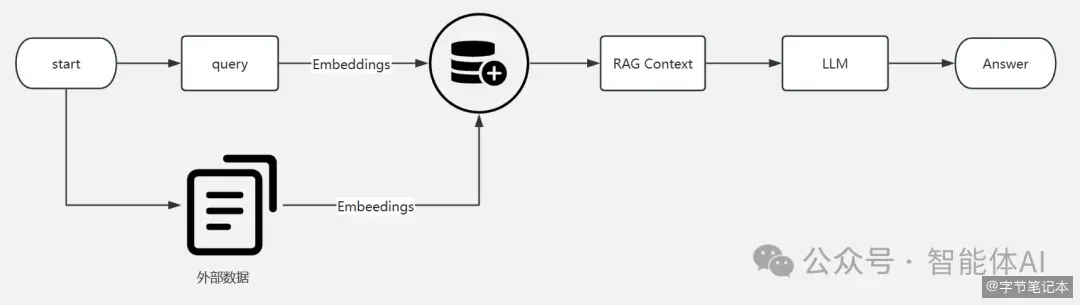
这个方案的精妙之处在于,它不需要在"检索精度"和"上下文完整性"之间做取舍。Child 保证查得准,Parent 保证读得全。两者通过关联关系自动联动,用户无感知。
对于长文档为主的 RAG 场景(企业知识库、法律文书、科研论文),Parent-Child 分割是目前性价比最高的优化手段,比换更好的 Embedding 模型或加 Reranker 更简单直接。
分享: