字节笔记本
2026年2月15日
Letta 发布 Context Repositories:基于 Git 的编码代理记忆系统
Letta 发布 Context Repositories:基于 Git 的编码代理记忆系统
Letta 推出 Context Repositories,彻底重构了 Letta Code 中的记忆机制。这是一个基于"程序化上下文管理和 Git 版本控制"的记忆系统,为 AI 编码代理带来了革命性的记忆管理能力。
核心创新
传统记忆方法将代理限制在 MemGPT 风格的记忆工具或虚拟文件系统操作中。Context Repositories 将代理上下文的副本存储在本地文件系统中,使代理能够利用其完整的终端和编码能力(包括编写脚本和生成子代理)来管理上下文,如渐进式披露和为学习而重写上下文。
Git 驱动的版本控制
Context Repositories 基于 Git 实现,每一次记忆变更都会自动通过信息丰富的提交消息进行版本控制。Git 跟踪还支持跨多个子代理的并发协作工作,代理可以通过标准 Git 操作管理学习上下文之间的分歧和冲突。
虚拟内存作为本地文件系统
文件是简单的通用原语,人类和代理都可以使用熟悉的工具操作。遵循 Unix 哲学,代理可以链式使用标准工具对记忆进行复杂查询,使用 bash 进行批处理操作,或编写脚本以编程方式处理记忆。
Letta API 上的代理运行在服务器上,但 Letta Code 代理将其记忆仓库克隆到本地文件系统,使代理拥有与客户端运行位置无关的本地记忆副本。
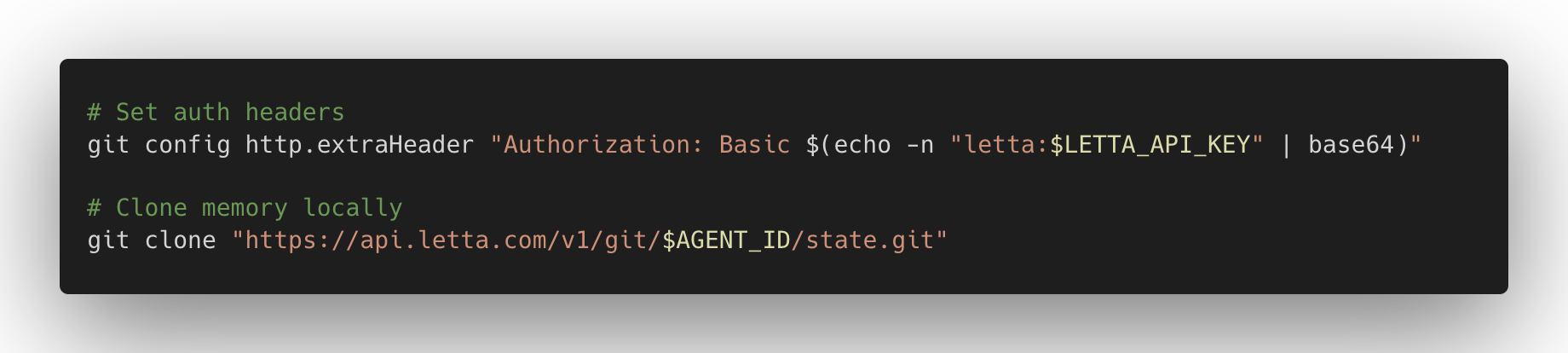
渐进式记忆披露
Context Repositories 中的文件专为渐进式披露而设计。文件树结构始终位于系统提示中,因此文件夹层次结构和文件名充当导航信号。每个记忆文件还包含描述其内容的 frontmatter,类似于 Anthropic SKILL.md 文件中的 YAML frontmatter。
system/ 目录指定哪些文件始终完全加载到系统提示中。由于代理对仓库具有程序化访问权限,它们可以通过重新组织文件层次结构、更新 frontmatter 描述以及在 system/ 中移入移出文件来管理自己的渐进式披露,以控制随着时间学习而固定到上下文的内容。
记忆代理与记忆集群
多代理系统已在复杂编码任务中证明非常有效。代理中的记忆形成和学习是单线程的:如果代理想要从数据或先前轨迹中学习,它会顺序处理,因为一直没有协调并发写入记忆的机制。Git 改变了这一点。
通过为每个子代理提供隔离的工作树,多个子代理可以并发处理和写入记忆,然后通过基于 Git 的冲突解决合并它们的变更。
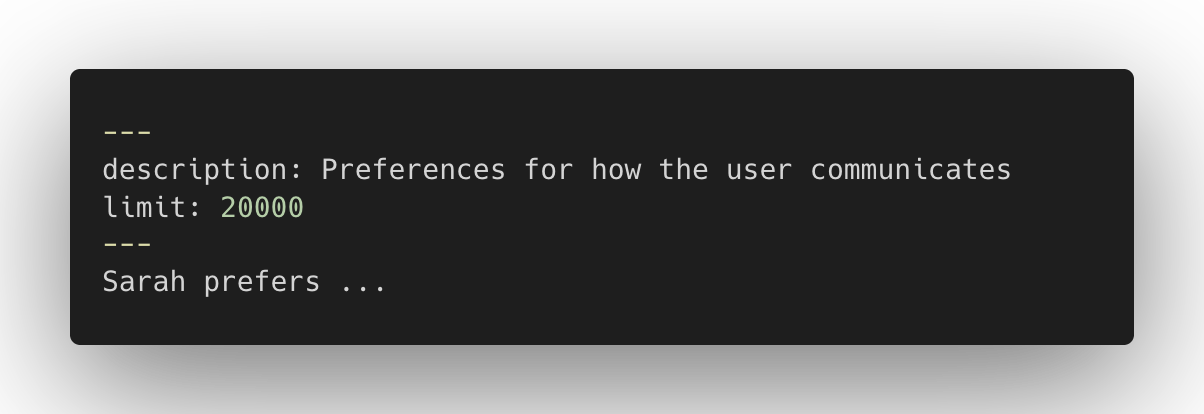
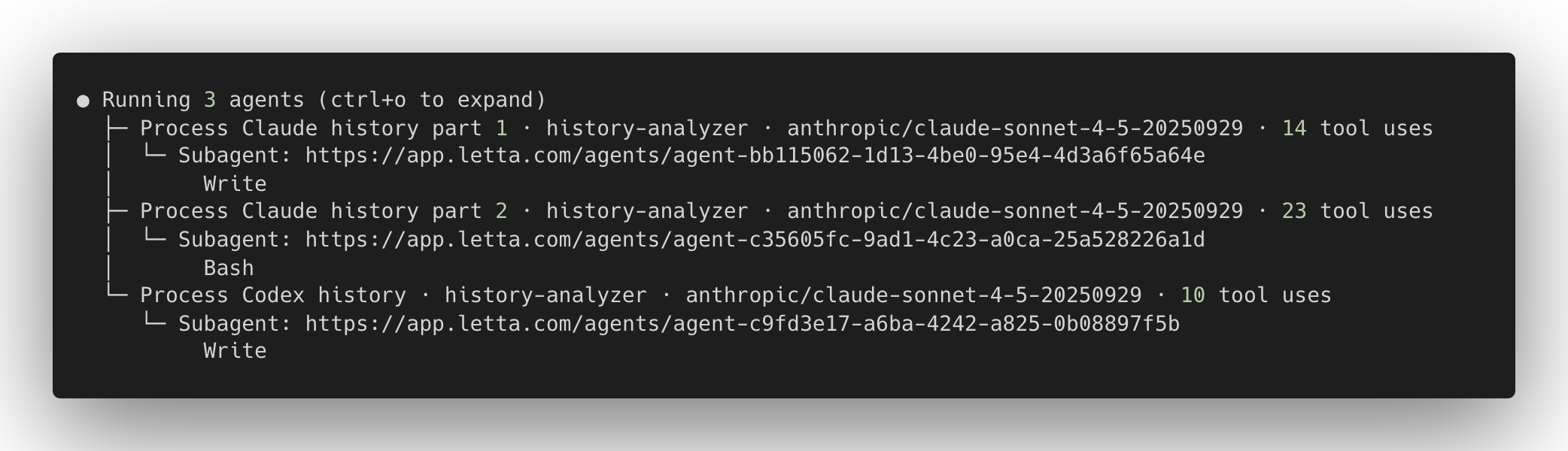
作为示例,Letta 更新了 /init 工具,可选择通过跨并发子代理分发处理来从现有的 Claude Code 和 Codex 历史中学习。每个子代理在自己的工作树中反思历史片段,结果合并回"主"记忆。
记忆技能
记忆仓库与记忆管理机制无关,但为记忆和上下文工程设计开辟了更多可能性。Letta Code 具有用于记忆管理的内置技能和子代理:
记忆初始化
通过探索代码库和审查历史对话数据来引导新代理,使用在 Git 工作树中工作的并发子代理创建初始层次化记忆结构。
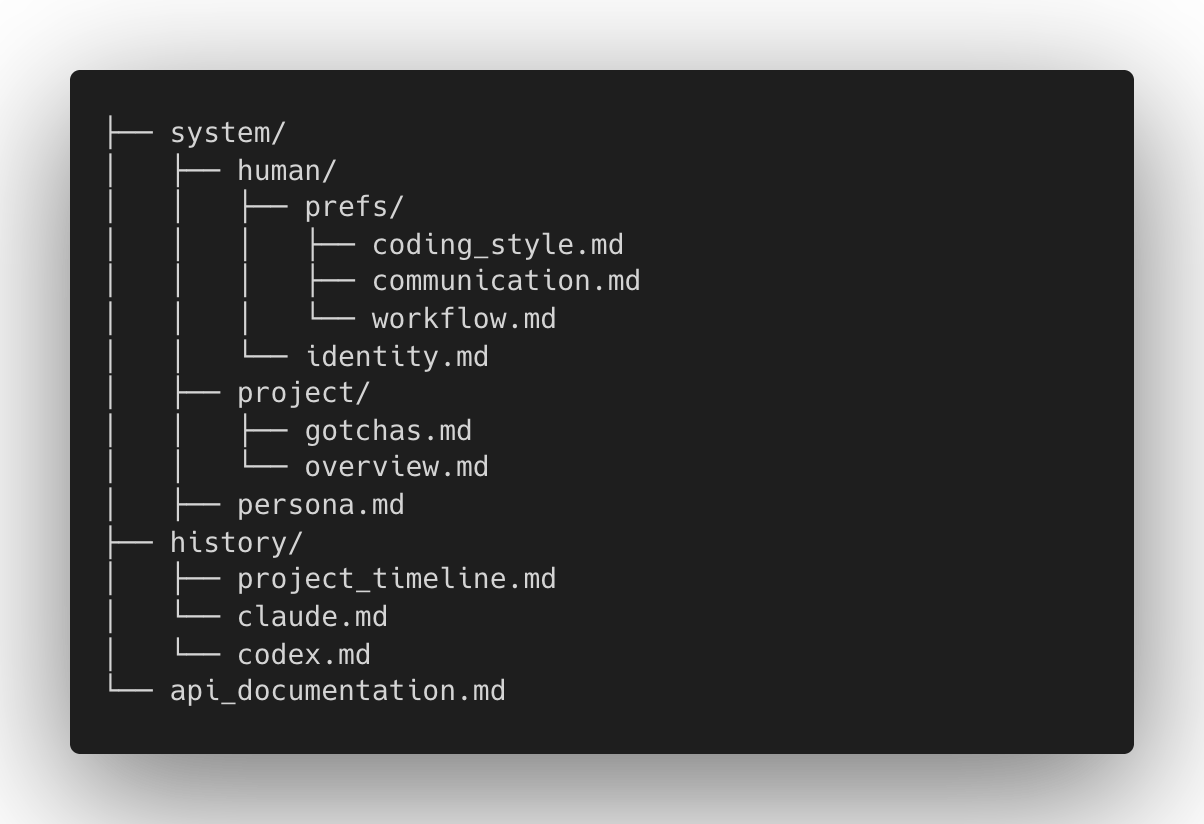
记忆反思
一个后台"睡眠时间"进程,定期审查最近的对话历史并将重要信息持久化到记忆仓库中,并附带信息丰富的提交消息。它在 Git 工作树中工作以避免与运行中的代理冲突,并自动合并回来。
记忆碎片整理
在长期使用过程中,记忆不可避免地变得不那么有条理。碎片整理技能备份代理的记忆文件系统,然后启动一个子代理重新组织文件,拆分大文件、合并重复项,并重组为 15-25 个聚焦文件的干净层次结构。
开始使用
你可以通过运行 /memfs 命令为代理启用记忆仓库。该命令将分离代理的 memory(...) 工具,并将现有记忆块同步到基于 Git 的记忆文件系统。
安装 Letta Code:
npm install -g @letta-ai/letta-code总结
Context Repositories 代表了 AI 代理记忆管理的重大进步。通过将 Git 的版本控制能力与本地文件系统的灵活性相结合,Letta 为编码代理创建了一个既强大又直观的记忆系统。这种方法不仅解决了传统记忆系统的局限性,还为未来的记忆工程创新奠定了基础。
原文链接: https://www.letta.com/blog/context-repositories
发布日期: 2026年2月12日