字
字节笔记本
2026年5月30日
用 GPT 那套提示词套路去调教 DeepSeek R1,反而会适得其反
API中转
¥120
大多数人对 DeepSeek R1 有一个误解:以为它和 GPT 一样,喂一套结构化提示词就能输出好结果。
实际上恰恰相反。DeepSeek R1 是一个推理模型,它的思考方式和传统大语言模型有本质区别。你给它一套"你是 xxx,你的能力是 xxx,我的要求是 xxx"的模板,反而会限制它的推理能力。DeepSeek 官方论文里明确说了:few-shot 会持续降低模型性能,零样本直接描述问题才是最佳实践。
这意味着什么?意味着过去两年积累的大部分提示词技巧,在 DeepSeek R1 上可能不适用,甚至起反作用。
但这不意味着提示词不重要。只是技巧的方向变了。
对于企业用户来说,真正有效的 DeepSeek 提示词技巧,核心只有一条:把 What 和 How 说清楚。不是用结构化模板约束它,而是用清晰的语境引导它。
比如"如何提高工作效率"这种模糊指令,换成"作为培训经理,需要为全国分公司制定在线营销学习项目,请设计一个每周 3 小时的集中培训规划,确保不同时区都能参与"。差别不在于格式是否结构化,而在于你给的信息量是否足够让模型理解真实场景。
其他几个经过验证的方向同样实用:在指令中加入资源约束("每天只有 2 小时可用")让方案更落地;把复杂需求拆成分步指令让推理更聚焦;提供真实数据而非让模型脑补。这些技巧的共同点不是"怎么写 prompt",而是"怎么描述问题"。
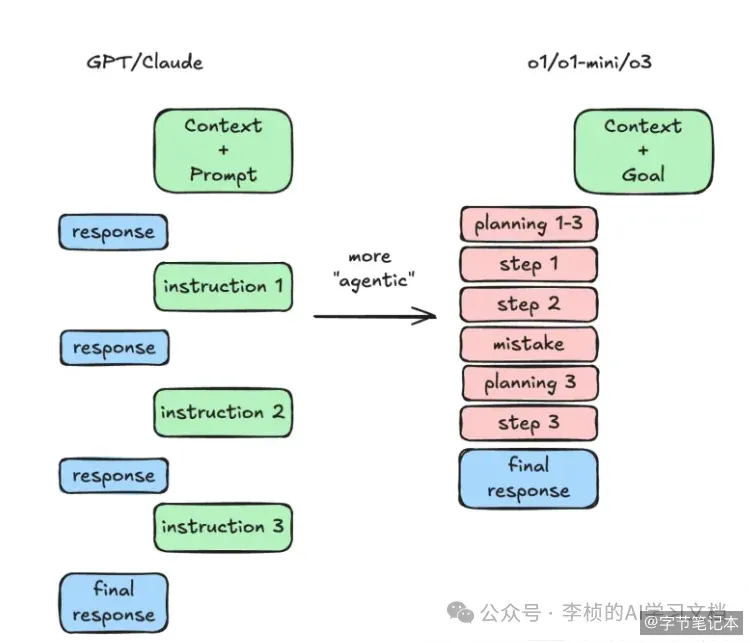
对于习惯了 GPT 结构化提示词的用户来说,切换到 DeepSeek R1 需要一次思维转换:从"教模型怎么回答"转变为"告诉模型你要什么"。前者是约束,后者是释放。而释放,才是推理模型真正擅长的事。
分享: